



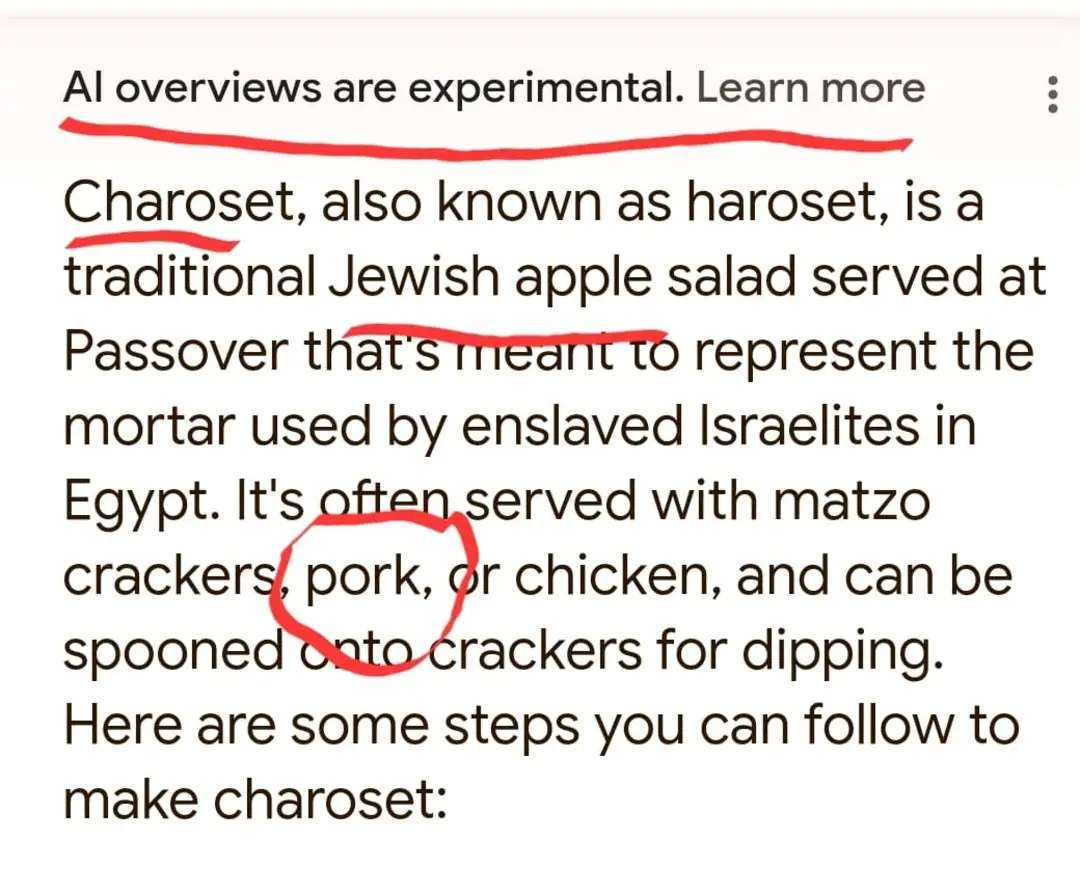
Someone once said “Logic is an organized way to go wrong with confidence.” LLM1 AI looks at logic and metaphorically says “Hold my beer and watch this”. Brad Delong has a post about ChatGPT where he tried to get it to give him the ISBN for a book and this goes horribly wrong

The professor suggests that you
[s]imply prefix every ChatGPT4 and related GPT MAMLM ChatBot answer with “The process of scanning the internet and my subsequent training leads me to calculate that a likely response by a human, if this question were asked of a human on a discussion forum on the internet, might well take the form of…”
This is good advice. But advice that is easily forgotten until you see someone post an example of an LLM getting things amusingly wrong so you laugh.
Phil, the funranium labs guy, who I know mostly because of the Picric Acid photo, coincidentally has a recent post where he extends that LLM issue to nightmare level.
With a moment’s contemplation after reading it, I just realized how spectacularly bad this could go if, for example, you went to do a search for an chemical’s Material Safety Data Sheet (MSDS) and a Large Language Model (LLM) gave you back some bullshit advice to take in the event of hazmat exposure or fire.
…
Your vanilla search for a normal MSDS will return several of varying qualities, that you then read and glean information from. Because an MSDS is primary information, it is authoritative. LLM generated instruction is secondary, theoretically deriving from those primary sources, but also prone to fabrication in places where it doesn’t know enough or doesn’t recognize the presentation.
and he has an example
I fed “how to respond to a vinyl chloride fire” into ChatGPT and it told responders to use a water fog on the water reactive chemical. This would have changed a train derailment/hazmat spill/fire emergency into a detonation/mass casualty/hazmat emergency. A+ performance, ChatGPT, you would have obliterated a town. In fairness, enough water fixes most any firefighting problem but at that point you’ve flooded what remains of a town that has been levelled by explosion and fire.
I will note that MSDSes are not by any means the only thing where fictional data could be extremely hazardous. Any number of repair manuals or DIY instruction guides could be equally erroneous and blindly following them could see the repair/construction go horribly wrong.
Consider a guide to doing maintenance on your old car. Asking an LLM to give you step by step instructions to change the transmission fluid on the 1984 model imported Toyota you just bought tenth hand (runz gud), with none of the original manuals, is pretty much the perfect usecase for LLMs in theory. Instead of having to watch 3 different youtube videos and read instructions translated poorly from Japanese into automotive specialist English (and you aren’t a car specialist), you ask your friendly LLM to give you the summary and it does so. Of course if the instructions don’t mention a critical step you could end up with a seized up engine, a fire, or some other disaster (insert your favorite #whynotboth meme here).
You are invited to consider other similar household tasks and how they too might go wrong and lead to, at best, mistakes that require significant expense to fix and at worst to exciting fires, explosions and the like. If you are like me you’ll come up with a new variant every few seconds.
I don’t see a way around this either. There’s no way to know if the LLM is lying or not without watching the 3 different youtube videos and reading the unclear instructions and if you have to do that the verify the correctness then there’s no point is asking the LLM in the first place. If it turns out the LLM used sources in a different language that it then translated (see Japanese car repair manual) then, unless you understand the different language you cannot in fact verify the correctness. You can’t even begin because you can’t search for web pages about “トヨタ自動車の修理マニュアル” because you can’t read the question text, let alone actually write it
Aside:

Unfortunately if Microsoft, Google and all continue to push LLMs as search engine assistants we are going to end up with a situation where someone asks an LLM for instructions like this, gets incorrect response, follows it and causes some kind of disaster.
Worse than the fact that there seems to be no good way to fix this, is that because of how LLMs scrape the internet, once a wrong answer has been generated it may end up becoming the only answer LLMs produce. Ed Zitron has a recent post on this:
AI models, when fed content from other AI models (or their own), begin to forget (for lack of a better word) the meaning and information derived from the original content, which two of the paper's authors describe as "absorbing the misunderstanding of the models that generated the data before them."
In far simpler terms, these models infer rules from the content they're fed, identifying meaning and conventions as a result based on the commonalities of how humans structure things like code or language. As generative AI does not "know" anything, when fed reams of content generated by other models, they begin learning rules based on content generated by a machine guessing at what it should be writing rather than communicating meaning, making it somewhere between useless and actively harmful as training data.
Let me provide a worked example that doesn’t involve deliberately feeding erroneous LLM output to other LLMs
Gullible Doofus asks his prefered LLM how to repair his gas stove.
The LLM responds with instructions that result in a small gas explosion
Somone (maybe a sooty Gullible Doofus, maybe a reporter…) posts on social media that LLM provided the following dangerous instructions with a tag like “Really excellent instructions for repairing a stove /sarc”
This post goes viral and hundreds of sites report it
These reports then get added into the next edition of training data for LLMs
The LLMs don’t recognize the /sarc tag
The LLMs now have hundreds of examples of “Really excellent instructions for repairing a stove” that are the same so their algorithms decide they must be good
Now anyone who asks an LLM gets the explosive answer
The LLM boosters all seem to think that throwing more CPU and more data at the problem will fix this. It won’t, all it will do is make it less common which means that people will be more likely to believe a wrong answer when it happens because now the answers are right 99 times out of 100 instead of 9 out of 10. See initial quote about going wrong with confidence.
LLM boosters may also think that they can evade the issue by stopping the LLMs from answering questions that are potentially dangerous like “what is the MSDS for …” but that isn’t going to work because there is no way to know what question will lead to a dangerous LLM hallucination. Something simple like “how do I remove grass stains from my white shirt” could (note I have not checked this) lead to advice that involves mixing a couple of common household cleaners/chemicals that react poorly together such as bleach and baking soda.
There is a fundamental knowledge problem: short of asking the LLM every conceivable question and checking the results we cannot know that the LLM will answer safely (let alone correctly) and we cannot ask every question.
This is an unsolvable problem.
There is NO WAY we can ensure that every LLM response is accurate
I repeat
This is an unsolvable problem. There is NO WAY we can ensure that every LLM response is accurate because LLMs just parrot a plausible sounding natural language synthesis of the data they hoover up from the internet. The LLM has no way to know that the answer is right, or even to understand at a semantic level what the question is.
We can however make it worse by not informing people that the search engine answer they got was from an LLM and therefore not trustworthy and you can be assured that Google, Microsoft & co will do precisely that. And they’ll sell ads for unreliable chinesium products as they do so.

As I basically said elsewhere, my fundamental problem is in the domain of behavior.
I do not trust myself to be smart enough to make a computer spit out the right answer the first time. This is largely my experience in screwing up simple tasks. I check, and recheck. On paper, in intelligence and in skill training, I may be in the more 'highly qualified' part of those distributions.
In practice, there are quite a lot of algorithms complicated enough I do not trust myself to implement and debug.
I have had a very wary eye on neural net methods for at least five to maybe as high as ten years. The stuff I was initially skeptical of also seemed to be handled cautiously enough. Also, the computational cost was too expensive for blindly doing stupid things. I still had very major issues with, say, legislative mandates that effectively required people to do it anyway, even if people are being killed.
So LLMs and image generation are a relative improvement in my eyes. Here are applications that work some of the time, and can never directly kill people without a bunch of extra human stupidity. Woohoo!
The problem is that quite a lot of people have been very badly raised and trained, and are more than capable of bringing that level of blind trust stupidity to the table. Folks who default to 'the experts are correct' or 'the computer is correct', and do not first check the problem against either the domain and skills of the expert, or against the inputs and algorithm of the computer. (With full awareness of GIGO.) (This excessive trust is perhaps downstream of power hungry idiots who see expertise as a route to controlling whether other people trust them and obey them. Either directly or by being politicians and 'leaders'.)
Microsoft's management choices WRT integrating sh!t into the OS have not been something I welcome.
I absolutely do not see 'breakaway synergism' leading to 'singularity' and Skynet sending terminators to kill me. (The people who want to have mass murder or government regulation to avoid this situation are basically not well mystics.)
What I do have concerns about is stupid management choices leading to the equivalent of phishing email exploits and those credentials used to hack PLCs, etc.
As it is in the domain of behavior, the fix is not technical, nor in government funding or mandate of technology.
If I use a government blockchain to evaluate trustability of statements, I already have scenarios where I know that government would misdirect my trust. Automating that to do more quickly and efficiently is stupid, before considering the cost/risk of that automation.
The fix is to the trust security flaw in behavior.
Which arguably is being patched invisibly anyway, because of other damaging 'hacks'.
I've noticed that when CoPilot gets something wrong, and you point it out, it get an attitude with you. ChatGPT is worse. It'll *agree* with you.