


AI = Actively Incinerating Cash?
What are the actual use cases for AI?

Note: Substack tells me this is too long for email. Please read in a browser or the app

Ed Zitron has been going on and on about how OpenAI & friends (Gemini, Copilot, Anthropic etc.) are burning through mountains of cash with no hope of profitability (more here). Given the figures he mentions, he seems to be understating the case:
2024 Revenue: According to reporting by The Information, OpenAI's revenue was likely somewhere in the region of $4 billion.
Burn Rate: The Information also reports that OpenAI lost $5 billion after revenue in 2024, excluding stock-based compensation, which OpenAI, like other startups, uses as a means of compensation on top of cash. Nevertheless, the more it gives away, the less it has for capital raises. To put this in blunt terms, based on reporting by The Information, running OpenAI cost $9 billion dollars in 2024. The cost of the compute to train models alone ($3 billion) obliterates the entirety of its subscription revenue, and the compute from running models ($2 billion) takes the rest, and then some. It doesn’t just cost more to run OpenAI than it makes — it costs the company a billion dollars more than the entirety of its revenue to run the software it sells before any other costs.
OpenAI also spends an alarming amount of money on salaries — over $700 million in 2024 before you consider stock-based compensation, a number that will also have to increase because it’s “growing” which means “hiring as many people as possible,” and it’s paying through the nose.
How Does It Make Money: The majority of its revenue (70+%) comes from subscriptions to premium versions of ChatGPT, with the rest coming from selling access to its models via its API.
The Information also reported that OpenAI now has 15.5 million paying subscribers, though it's unclear what level of OpenAI's premium products they're paying for, or how “sticky” those customers are, or the cost of customer acquisition, or any other metric that would tell us how valuable those customers are to the bottom line. Nevertheless, OpenAI loses money on every single paying customer, just like with its free users. Increasing paid subscribers also, somehow, increases OpenAI's burn rate. This is not a real company.
The New York Times reports that OpenAI projects it'll make $11.6 billion in 2025, and assuming that OpenAI burns at the same rate it did in 2024 — spending $2.25 to make $1 — OpenAI is on course to burn over $26 billion in 2025 for a loss of $14.4 billion. Who knows what its actual costs will be, and as a private company (or, more accurately, entity, as for the moment it remains a weird for-profit/nonprofit hybrid) it’s not obligated to disclose its financials. The only information we’ll get will come from leaked documents and dogged reporting, like the excellent work from The New York Times and The Information cited above.
He helpfully points out that OpenAI, while the biggest name in the space, is just the biggest loser and that all its competitors seem to be incinerating cash at similar rates.
Zitron points to an article that says Microsoft loses an average of $20/month on a github copilot subscription and has data regarding Anthropic, Perplexity and Google Gemini as well. None of them seem close to breaking even on OPEX let alone paying back the enormous billions of CAPEX spent training the models. I am reminded of the old joke about selling at a loss and making it up on volume.
He lists a few use cases and points out that in most cases they are not worth the money people actually pay for them, let alone the higher cost of providing the service because all of them are inherently unreliable:
Moreover, OpenAI (like every other generative AI model developer) is incapable of solving the critical flaw with ChatGPT, namely its tendency to hallucinate — where it asserts something to be true, when it isn’t. This makes it a non-starter for most business customers, where (obviously) what you write has to be true.
Case in point: A BBC investigation just found that half of all AI-generated news articles have some kind of “significant” issue, whether that be hallucinated facts, editorialization, or references to outdated information.
And the reason why OpenAI hasn’t fixed the hallucination problem isn’t because it doesn’t want to, but because it can’t. They’re an inevitable side-effect of LLMs as a whole.
Gosh I do believe I wrote something about that last year:
LLM Considered Harmful

Someone once said “Logic is an organized way to go wrong with confidence.” LLM AI looks at logic and metaphorically says “Hold my beer and watch this”. Brad Delong has a post about ChatGPT where he tried to get it to give him the ISBN for a book and this goes horribly wrong
LLM AI - what the average man on the street thinks AI is, is fundamentally broken this way and people keep on finding out the hard way that it will invent stuff. For example legal cases:
Morgan & Morgan's AI troubles were sparked in a lawsuit claiming that Walmart was involved in designing a supposedly defective hoverboard toy that allegedly caused a family's house fire. Despite being an experienced litigator, Rudwin Ayala, the firm's lead attorney on the case, cited eight cases in a court filing that Walmart's lawyers could not find anywhere except on ChatGPT.
These "cited cases seemingly do not exist anywhere other than in the world of Artificial Intelligence," Walmart's lawyers said, urging the court to consider sanctions.
[…]
Reuters found that lawyers improperly citing AI-hallucinated cases have scrambled litigation in at least seven cases in the past two years. Some lawyers have been sanctioned, including an early case last June fining lawyers $5,000 for citing chatbot "gibberish" in filings. And in at least one case in Texas, Reuters reported, a lawyer was fined $2,000 and required to attend a course on responsible use of generative AI in legal applications. But in another high-profile incident, Michael Cohen, Donald Trump's former lawyer, avoided sanctions after Cohen accidentally gave his own attorney three fake case citations to help his defense in his criminal tax and campaign finance litigation.
Some AI models, if queried correctly, will show their working so that the user can verify what has been found. Perplexity seems to do this by default which is nice (see example) and which, as a result, shows the limitations of the product because it doesn’t in fact mention the Ars Technica story I quoted above even though it does link to an older ars article.
Where’s The Money?
I also used perplexity recently to generate a general marketing document for $dayjob using the deep research feature and the general opinion of myself and the people I shared it with was that this was good. But it wasn’t so good that we are rushing to sign up for an enterprise account. The problem for the LLM AI people is that we don't have enough of such questions to want to pay and we get one free deep research query a day which is more than enough. Would we at $dayjob pay say $5 a response for that? probably not, though in theory it would be cheaper than our own time, because it's not a must have. So we're a part of the problem. And I think that’s the key. There’s no obvious “must have” need here. Most business sorts of people don’t need it, and if they do need it, they either don’t need it enough to pay for it, or they aren’t willing to pay enough to cover costs.
This also applies, only more so, to the Ghibli memes and so on, such as this picture of Uncle Don:

Yes it’s fun. And yes it saves would be meme makers a lot of time and effort and photoshop knowledge. But it probably isn’t something most of us will pay for, although some people (e.g. the ones creating book covers) will do so. From Ed’s second article it seems that mass Ghiblification is causing OpenAI to spend even more money and, since the creation process is free, they get zero payment for it all:
Anyway, in the last 90 days, Sam Altman has complained about a lack of GPUs and pressure on OpenAI's servers multiple times. Forgive me for repeating stuff from above, but this is necessary.
On February 27, he lamented how GPT 4.5 was a "giant, expensive model," adding that it was "hard to perfectly predict growth surges that lead to GPU shortages." He also added that they would be adding tens of thousands of GPUs in the following week, then hundreds of thousands of GPUs "soon."
On March 26, he said that "images in chatgpt are wayyyy more popular than [OpenAI] expected," delaying the free tier launch as a result.
On March 27, he said that OpenAI's "GPUs [were] melting," adding that it was "going to introduce some temporary rate limits" while it worked out how to "make it more efficient."
On March 28, he retweeted Rohan Sahai, the product team lead on OpenAI's Sora video generation model, who said "The 4o image gen demand has been absolutely incredible. Been super fun to watch the Sora feed fill up with great content...GPUs are also melting in Sora land unfortunately so you may see longer wait times / capacity issues over coming days."
On March 30, he said "can yall please chill on generating images this is insane our team needs sleep."
On April 1, he said that "we are getting things under control, but you should expect new releases from openai [sic] to be delayed, stuff to break, and for service to sometimes be slow as we deal with capacity challenges." He also added that OpenAI is "working as fast we can to really get stuff humming; if anyone has GPU capacity in 100k chunks we can get asap please call!"
These statements, in a bubble, seem either harmless or like OpenAI's growth is skyrocketing — the latter of which might indeed be true, but bodes ill for a company that burns money on every single user.
Anecdotally one of the bigger uses for AI seems to be by students using it to write essays or otherwise assist with homework. This sort of task is something that AI engines can do so well that academia as a whole is struggling to get a handle on how to stop it. This is because the AI generated essay is not teaching the student anything except that he or she can party away and let the computer do the work for them. Not only does this practice harm education, it costs the AI companies significant money to answer the questions and will probably eventually lead the students astray because some of them will later put their trust in an AI hallucination and suffer from it. Even if a student buys his own pro account subscription it is likely that his queries will cost the AI company more in terms of compute cost etc. than his monthly revenue.
In this case where AI companies are consuming investor cash while actively sabotaging the user’s education the value removal caused by using AI is unprecedented.
Even drug dealers who give the first hit away for free expect to make money on the victim sometime later. AI companies do not seem to have that expectation. Or at least if they do, the expected payback period is in years if not decades.
In an article dripping with coastal condescension to the hicks of Flyoverstan, Ars Technica reported that less educated areas are using AI tools more. While the article, and underlying research seems to be going straight into stereotypes, the actual use case of getting an AI LLM to turn your bullet points into a letter/email is not unreasonable. In fact given some of the god awful emails I’ve received from allegedly literate people while I do $dayjob this is may actually be necessary. I do wonder how some of these people graduated high school, let alone got a bachelors degree and (in one case) an MBA. But I don’t think most people will be willing to pay $20/month for such a service because they only need it to write one or two things a month. As with the students and artists, the ones that are willing to pay $20/month are probably going to use it so much that $20/month fails to pay for the opex cost of their usage.
I do think that a lot of office busywork of the sort MBAs love will be ideal candidates for AI-ification and the reports generated will likely be no less inaccurate than the ones MBAs create or get interns or other underlings to do for them. 1
Another big use for AI is to generate AI slop as filler for search engine optimization and ad monetization scamming. If you’ve noticed that many search engine responses are now junk (and if you haven’t then I suggest you go to google and try a few queries for moderately technical information on a subject you are familiar with) then that’s largely due to AI generated pages that the search engine bots then consume. While this isn’t as bad as the AI usage by students, it also entirely fails to benefit the world as a whole. From a recent cloudflare blogpost:
AI-generated content has exploded, reportedly accounting for four of the top 20 Facebook posts last fall. Additionally, Medium estimates that 47% of all content on their platform is AI-generated.
And of course, as that same blogpost goes on to discuss, the AI bots that try to ingest everything all the time are themselves a net drag on many websites. Ignoring the questions of copyright infringement and the like, just the load of the AI bots continually scraping websites can act as a kind of DDOS on the sites themselves.
Finally using public AI services is a security risk. That’s true even before we get to the seriously spooky Microsoft Recall which plans to act like the stalker in that police song and track “every step you take, every move you make”. Users regularly upload data to the public AI services that are confidential/private and other AI researchers/users seem to regularly find ways to extract data from AI services that they shouldn’t which can include that confidential data that has been uplaoded. And that, of course, is before the AI companies themselves use that data in their training models or, in the case of the Chinese Deepseek AI, apparently just copy the whole lot to some other mystery servers in West Taiwan.

There are in fact companies whose business model is (in part) to detect and stop rogue use of AI
There are undoubtedly good uses for AI, even good uses for LLM AI. ESR has been Xeeting recently about his use of an AI coding assistant, for example, and there are undoubtedly other similar use cases. But the public AI organizations seem to be spending enormous amounts of money to provide services that people won’t pay for, using data they ought to pay for, and a significant proportion of the output of these services is actively bad for the user and/or the internet as a whole.
Lets talk money invested
OK so just how much money are we talking about? and isn’t this just the same as google/twitter/uber and so many other tech companies which take a while to become profitable?
Maybe. Or maybe not. Before AI took off the companies that had taken the most amount of investment dollars and not made a profit were probably the ride share companies, Uber and Lyft. Over some 15 years Uber took in (according to Crunchbase) $32.5B in 34 funding rounds with the last, in January this year, of $2.3B from Bill Ackman as well as raising $8.1B in its IPO. Lyft has taken 5.3B in investments and raised $2.3 in its IPO (which BTW has been a disaster for investors, unlike Uber)
Uber made an actual profit for the first time in FY2023 and a bigger one last year (FY 2024), but it only had some $7B in actual cash or short term investments at Dec 31, 2024. It also, as of the same date, had an accumulated deficit of some $20B. This is, BTW a considerable improvement over 2023 where the deficit was $30B, but Uber still has some way to go to make a positive return on the money invested. Lyft seems to be struggling a bit and not making as much money, but it did generate $766M in free cash flow in 2024, which suggests that it too is probably finally profitable, whether or not the financial accounting shows profits or not.
However between the two of them, they raised some $48B from investors either via IPO or investment rounds, in 15+ years. And while there’s some financial questions outstanding on the whole, they are now beginning to provide an actual positive return on investment to their investors. So payback is coming, it’s just taken well over a decade to arrive.
Open AI is a whole order of magnitude more cash hungry. Since, I think, 2019 until the end of last year they had raised $21.9B, roughly half of that last October, and blown it all so much that at the end of last month they received (allegedly) an additional $40B investment from Softbank.
Ed Zitron points out in his most recent article that the $40B is contingent on a ton of things and not all of it is due immediately. In fact just $10B is due any day now with the rest to show up next year assuming Open AI manages to turn itself into a real company instead of its current odd non-profit status. That round valued Open AI at an astounding $300B which is not unadjacent to Tesla’s market capitalization in 2022 - a time when Tesla had made many thousands of cars and had annual revenues of around $80B. It is also approximately twice Uber’s current market cap and Uber had revenues of some $44B in 2024. Open AI by contrast had $4B in revenue in 2024 and made a $5B loss on that money
Open AI while probably the biggest money sink in AI is far from being the only one. A significant fraction (something like 50%) of the total capex spending by what Bloomberg calls “big tech” in the last couple of years (and predicted additions in the next few) is going towards AI infrastructure
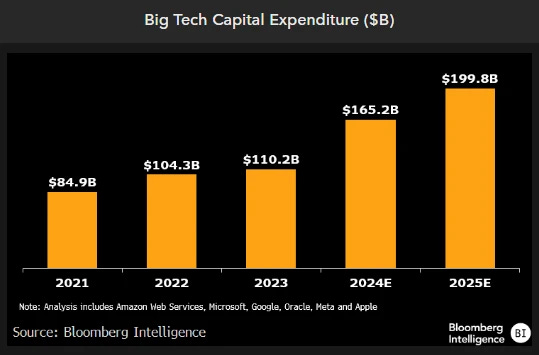
Our analysis of the top tech companies shows over $90 billion in incremental capital spending in 2024-25 vs. 2023, dedicated mostly to expanding generative-AI infrastructure. This group, which includes Amazon Web Services, Microsoft, Google, Oracle, Meta and Apple, added an average of $14 billion annually to capex from 2020-23. The $90 billion increase over a two-year period illustrates the increased demand and interest by clients, and appears different than other hyped technologies, such as the metaverse.
Then there’s Musk’s xAI aka grok ($12.4B funding to date) as well as Anthropic ($18B funding to date) and all the other LLM AI startups who are also spending megabucks as well as companies like CoreWeave who are building out data centers full of GPUs for AI companies to rent. CoreWeave just raised $1.5B in an IPO that was delayed and originally was expected to raise at least double that and it also has significant debt (~$10B) as well as various other investment rounds. CoreWeave, like Open AI, loses money heavily by the way.
So put it all together and AI has seen a good $50B-$100B spent on it in the last few years and will see at least $100B in the next couple. That’s just in the US. I’m ignoring, because I have no easy way to get the figures, how much the Chicoms are spending or how much other countries may be.
Probably the total cumulative investment will be on the order of a quarter of a trillion dollars by US companies.
Outside of the US federal budget, that’s a hell of a lot of money and, as I point out above, a good order of magnitude more than any previous technology.
To compare with other growing fields: SpaceX, BTW, has had funding of ~$12B excluding its commercial deals with NASA etc. So to put it another way xAI has received about the same amount of funding as SpaceX and both Anthropic and Open AI have received much more, but none have a product that shows any sign of making money. Neither do the enormous investments made by Microsoft, Google, Apple and Meta. And they will need to make GDP altering amounts of money in order for the investors to get payback. Even to break even they’ll need to get a quarter trillion dollars profit from users. Since we assume these investors expect more than that we’re looking at a requirement to make something like a trillion dollars in profit over the next decade. Note that Google currently makes ~$100B in net earnings (profit) per year and Meta makes ~$60B so what that implies is that collectively AI needs to generate roughly the same amount of net earnings as Google every year for the next decade.
This is from a technology that has yet to get more than around $10B in revenue per year and which is spending around $2 for every dollar of income.
There is nothing wrong with losing money during the start up phases of a new technology or company. That’s actually normal. But most new technologies don’t require a quarter trillion dollars of investment before they start breaking even and that quarter trillion assumes that in a couple of years there will be enough users willing to pay enough money per month to start breaking even. In fact no other new technology has ever required anything like that amount. The social media companies and the ride share companies each needed less than 10% (OK uber needed slightly more than 10%) of that amount and at the time, a mere decade ago, we thought those levels of investment was enormous.
If it turns out there’s no way to monetize LLM AI profitably then Silicon Valley and Wall St. will have to figure out how handle the fact that they just incinerated a quarter trillion dollars for nothing. And I emphasize that at present there seems to be no killer app for AI. There is no must have use for it - and Ghiblified pictures of world leaders are not a must have use because no one will pay for them.
If you detect that I am unimpressed with the accuracy and usefulness of such reports, no matter who or what creates them, then congratulations on being an astute reader!
So far, seems like the destruction of the Internet (all information at anyone's command) is the output of generative AI.
Seems to me the AI in Academia problem has a simple solution; go back to oral and blue book exams.
AI's a tool and as a time saver it may prove it's worth. Calculations that might take me up to half a day including trips back and forth to the bookshelves looking up formulas checking tables etc., even chatbot does in a few minutes and as you noted, shows it's work so I can check and verify. Admittedly what I'm doing is trivial but it does suggest possible value of the tool.
It hadn't occurred to me that AIs could code (I know a fact that should be self evident.) until I asked deepseek about CAD programs, our discussion leading it to writing code to build a 3D model in OpenSCAD.
Value vs cost though? DamnedifIknow.